The Kusto Query Language (KQL) is ideal for analyzing time series data stored in Azure Data Explorer (ADX).
Setup
For the examples in this article, we will use a table created with the following ADX commands:
.drop table droneData .create-merge table droneData ( DroneId:int, TimeStamp:datetime, Longitude:decimal, Latitude:decimal, BatteryLife:decimal ) .ingest inline into table droneData <| 1, datetime(2022-01-10 10:45:00), -73.988888888888888, 40.742222222222222, 100.0 1, datetime(2022-01-10 11:15:00), -73.978820800000000, 40.741862453111111, 99.9 1, datetime(2022-01-10 11:30:00), -73.978800000000000, 40.741862453112222, 99.8 1, datetime(2022-01-10 12:45:00), -73.970000000000000, 40.741862453122222, 99.7 1, datetime(2022-01-10 12:00:00), -73.960555555555555, 40.741862453122222, 99.6 1, datetime(2022-01-10 12:15:00), -73.960000000000000, 40.741862453122222, 99.5 1, datetime(2022-01-10 12:30:00), -73.960000088888888, 40.741862453122222, 99.4 1, datetime(2022-01-10 12:45:00), -73.960000055555555, 40.741862453122222, 99.4 1, datetime(2022-01-10 13:00:00), -73.960000011111111, 40.741862453122222, 99.3 1, datetime(2022-01-10 13:15:00), -73.955555555555555, 40.741862453122222, 99.2 1, datetime(2022-01-10 13:30:00), -73.950000000555555, 40.741862453122222, 99.2 1, datetime(2022-01-10 13:45:00), -73.960000000000000, 40.741862453122222, 99.0 1, datetime(2022-01-10 14:00:00), -73.960555555555555, 40.741862453122222, 98.9 1, datetime(2022-01-10 14:15:00), -73.960555555555555, 40.741862453122222, 98.8
Ordering
To use the time series functionality, it is important to
- Have a column string a time value
- Sort your data by that time value column
Getting the Previous value
After you have sorted the data, KQL provides the prev function that allows you to retrieve the value of any column in the sorted order. You can only use this function if your data has been sorted using the order by clause.
The syntax is
prev(column)
where column is the name of the column from which to retrieve the previous row's value.
The following example retrieves the battery life from the previous row; then, calculates the delta between the current row and the previous row.
droneData | order by TimeStamp asc | project DroneId, TimeStamp, Longitude, Latitude, BatteryLife, PrevBatteryLife = prev(BatteryLife) | extend BatteryLifeChange = BatteryLife – PrevBatteryLife
The results of this query are shown in Fig. 1
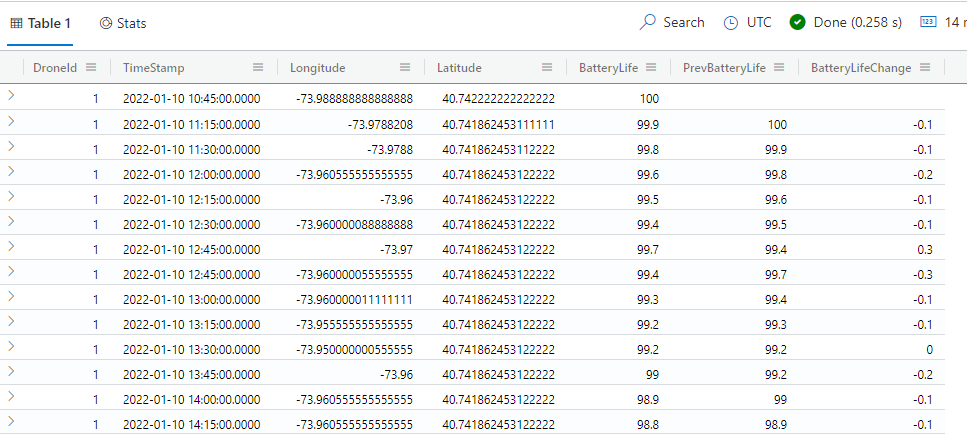
Fig. 1
By default, the prev() function returns a value 1 row prior to the current row. However, you can specify to go back any number of rows by providing an optional offset argument. The syntax is:
prev(column, offset)
By default, the prev function returns null, if there is no previous value (for example, for the first row in the dataset). However, you can provide a different default for these cases with the optional default_value parameter. The syntax is:
prev(column, offset, default_value)
As you may have guessed, there is also a next function that works exactly the same way, except that it returns a value from the next row in the series, rather than the previous one.
Summarizing Data Into Bins
KQL provides the bin function to use when aggregating data. Typically, when you aggregate data, you use the by clause group by a field or fields in the table. The bin() function allows you to group time series data by a time increments. If you have data points for every hour, you can return results for each 15-minute interval. The syntax is:
bin(value,roundTo)
where:
- value is a column containing datetime values
- roundTo is a timespan indicating how far apart each grouping should occur
An example will help. The following query returns one row for each 1-hour interval, even though our sample data contains values every 15 minutes.
droneData | summarize arg_max(TimeStamp, DroneId, Longitude, Latitude, BatteryLife) by bin(TimeStamp, 1h)
The results of this query are shown in Fig. 2
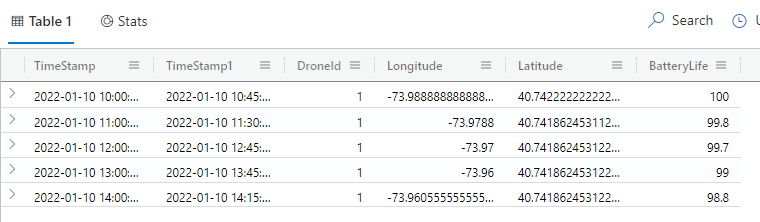
Fig. 2
If you have multiple rows within your specified interval, it is reasonable to ask which row's values will be returned. The arg_max operator in the example above takes care of this. It tells Kusto to return the row with the maximum TimeStamp value in that interval. The first argument in arg_max specifies which column to consider when determining the maximum and the other arg_max arguments determine what other column values to return.
The bin function can also be used to group numeric data, so that you only show one row per 100 items, for example.
Conclusion
There are many other KQL features to help you work with Time Series data, but this article covered the ones that my team has found most useful.