KQL provides a way to retrieve datasets from your ADX tables. Like SQL, KQL provides the ability to filter, sort, join and order data.
KQL is a read-only language - that is, KQL queries can read data; but they cannot update or delete data. For this reason, KQL is almost always used to return a dataset - a collection of rows and columns that provide insights into your data.
Setup
For the examples in this article, we will use a table created with the following ADX commands:
.drop table customers .create table customers ( FullName:string, LastOrderDate:datetime, YtdSales:decimal, City:string, PostalCode:string ) .ingest inline into table customers <| 'Bill Gates', datetime(2022-01-10 11:00:00), 1000000, 'Redmond', '98052' 'Steve Ballmer', datetime(2022-01-06 10:30:00), 150000, 'Los Angeles', '90305' 'Satya Nadella', datetime(2022-01-09 17:25:00), 100000, 'Redmond', '98052' 'Steve Jobs', datetime(2022-01-04 13:00:00), 100000, 'Cupertino', '95014' 'Larry Ellison', datetime(2022-01-04 13:00:00), 90000, 'Redwood Shores', '94065' 'Jeff Bezos', datetime(2022-01-05 08:00:00), 750000, 'Seattle', '98109' 'David Giard', datetime(2022-01-02 09:01:00), 1.50, 'Chicago', '60605'
See this article for information on managing tables with ADX commands.
You can run the examples in this article in either the ADX Data Explorer web page or in Kusto.Explorer - a rich client Windows application that you can download for free from here.
Syntax
KQL does not require any terminator, such as a semicolon to indicate the end of a command. A blank line between commands is sufficient.
Each clause of a KQL query is separated by a pipe character ("|"). Reading from left to right, the output of each clause serves as the input of the next clause. So, you can apply a filter before you sort before you take 10 rows. Sometimes, the order is important.
Data Source
The first thing in a KQL query is the source of the data you are querying. This can be a table, a materialized view, or an in-memory dataset. Simply typing the name of a table will return all the rows and columns in that table. So, this is a valid KQL query that returns all rows in the customers table.
customers
The results of this simple query are shown in Fig. 1.
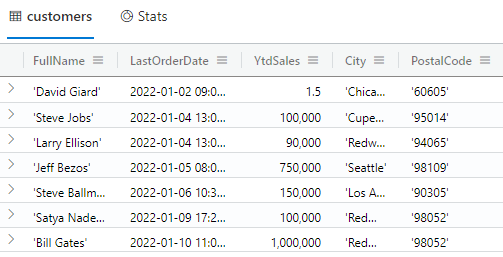
Fig. 1
Filtering
Use the where clause to filter the rows returned by a query. The where keyword, followed by a boolean expression tells Kusto to return only rows for which that expression is true.
The following query returns only the customers with YTDSales of at least $100,000:
customers | where YtdSales >= 100000
The results of this query are shown in Fig. 2.
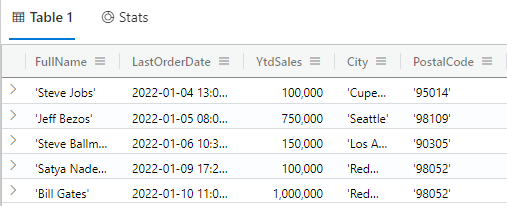
Fig. 2
Sorting
The order by clause sorts the output of a query. Add to your query "order by ", followed by a comma-delimited list of columns or expressions. The output will be sorted in the order specified. In case of a tie for the first expression in the order by list, the output will be sorted by the second expression and so on. By default, sorting is in descending order. To explicitly specify in which direction to sort, add "asc" (for ascending order) or "desc" (for descending order) following the column or expression.
The following query sorts the customers by PostalCode in ascending order, then by LastOrderDate in descending order:
customers | order by PostalCode asc, LastOrderDate
The results of this query are shown in Fig. 3.
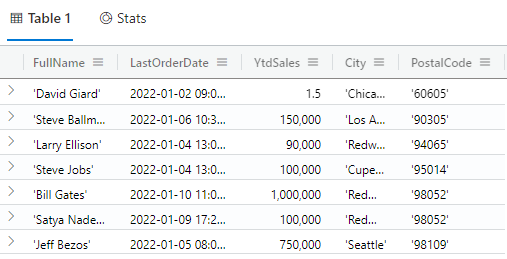
Fig. 3
Limit Rows Returned
Use the take keyword to limit the number of rows returned. This can be helpful to reduce the time a query executes or for doing a "TOP-N" query, when combined with the order by clause.
The following query returns the customers with the top 3 YtdSales values:
customers |order by YtdSales desc | take 3
The results of this query are shown in Fig. 4.
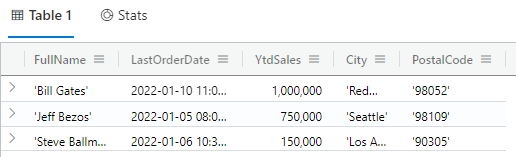
Fig. 4
Limit Columns Returned
By default, KQL will return every column in the source dataset.
Use the project keyword to select which columns to return. The syntax is "project" followed by a comma-delimited list of column names or expressions.
The following query returns only the FullName and LastOrderDate columns of every row in the customers table:
customers | project FullName, LastOrderDate
The results of this query are shown in Fig. 5.
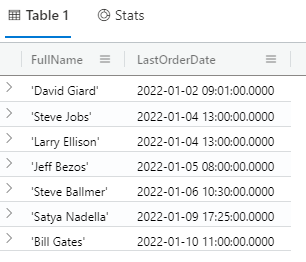
Fig. 5
Calculated Columns
You can add expressions to your projections by simply adding to the list and (optionally) assigning a name to the calculated column. Here is an example:
customers | project FullName, LastOrderDate, NextDay=LastOrderDate + 1d, YtdSales, RemainingQuota=2000000-YtdSales
The results of this query are shown in Fig. 6.
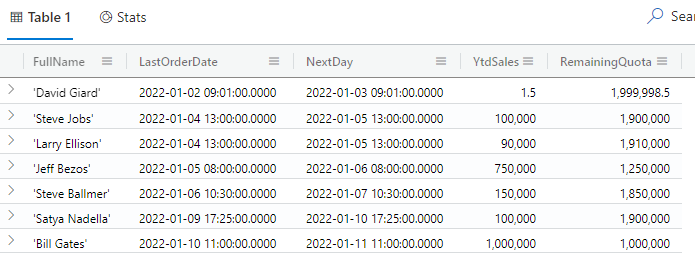
Fig. 6
Another way to add columns is using the extend keyword. This is useful if you want to use a calculated value as input into another expression. Here is an example:
customers | project FullName, LastOrderDate, NextDay=LastOrderDate + 1d, YtdSales, RemainingQuota=2000000-YtdSales| extend expectedSales = RemainingQuota * 2
The results of this query are shown in Fig. 8.
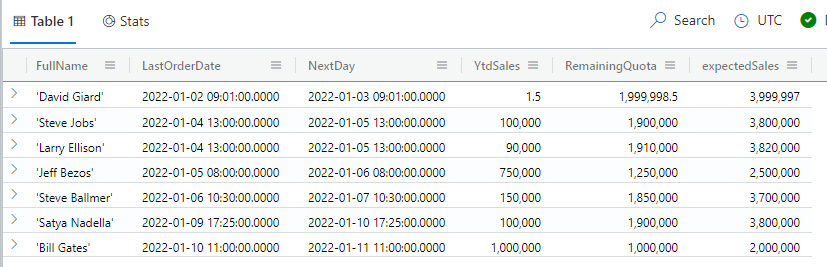
Fig. 7
The extend keyword is also useful if you want to add an extra output column and keep all the existing columns, without bothering to re-type them.
Here is an example:
customers | extend NextDay=LastOrderDate + 1d
The results of this query are shown in Fig. 8.
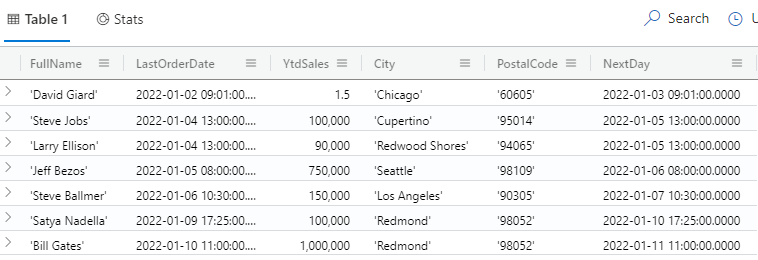
Fig. 8
Aggregation
Use the summarize keyword to aggregate data. The syntax is
| summarize
by
where
Here are some useful aggregation functions to use in your expressions
| avg() | Average of all values of a column for a group |
| min() | Minimum value of a column for a group |
| max() | Maximum value of a column for a group |
| count() | The number of rows for a group |
| arg_max(), arg_min() | Finds the row with maximum or minimum value of a given column for a group and returns other column values for that row |
You can see a full list of aggregate functions here.
Here is an example, showing the numer of customes and average YTDSales for each Postal Code in our table.
customers | summarize count(), avg(YtdSales) by PostalCode
The results of this query are shown in Fig. 9
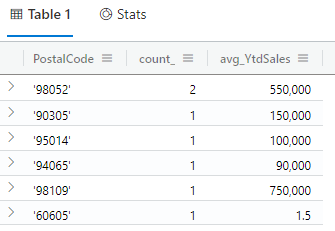
Fig. 9
Limits
KQL has a hard limit of 500,000 rows and 64MB. In other words, even if your query would return a million rows, Kusto will throw an exception. If you are writing queries that return this much data, it may serve you to rethink your filters and what information you are trying to extract.
A Note About SQL
If you are already familiar with SQL, Kusto provides a quick way to convert SQL queries into Kusto queries.
Simply type “explain”, followed by a SQL query and ADX will output a corresponding KQL query
Conclusion
This article discussed some of the basic concepts and syntax of KQL queries. In a future article, we will cover some advanced functionality and functions.